Overkill AI Waste Classifier: Phase 2 - Giving the Machine Sight

Continuing from the last phase of our journey, this time we will make the Pi camera "see." With the wiring and main functionality in place, it's time to connect it to a Vision Language Model (VLM).
Utilizing a Vision Language Model (VLM)
Modern AI models can process various forms of data, including text, images, videos, and even sound. While Large Language Models (LLMs) are typically focused on text, they can be extended to accept images as input. These are known as Vision Language Models (VLMs).
Technically, the image isn't just converted to text like Base64 (that's just for sending it over the network). Instead, the VLM uses a special component called a vision encoder to transform the image into a numerical representation that the language model can understand. VLMs have become incredibly capable for their size, with popular open-source examples like LLaVA, Idefics, Qwen-VL, and Moondream.
However, running these models on a small device like a Raspberry Pi presents a significant challenge due to limited memory (VRAM). We explored two primary methods to tackle this:
- On-Device Inference: Running Moondream (moondream:1.8b), a model specifically designed for its efficiency on edge devices. We'll see how it performs on the Pi's hardware.
- Remote Inference: Offloading the work to a more powerful PC with a dedicated GPU running Qwen-VL (qwen2.5vl:7b). This model is larger and more powerful, and I've had great success with it for image classification tasks.
- Cloud Inference: A third option is to utilize a cloud-based inference engine from services like HuggingFace, Replicate, or AWS. We decided not to pursue this method for now in order to maintain focus on local and self-hosted solutions.
Test Bed Setup
For both methods, I used the same standardized prompt to ensure the model returned a clean JSON object:
Analyze this image and classify the waste item into one of these categories:
1. Rubbish (waste_type: 1) - Non-recyclable items like soft plastics, food wrappers, broken ceramics
2. Recyclable (waste_type: 2) - Paper, cardboard, hard plastics, glass, metals
3. Organics (waste_type: 3) - Food scraps, garden waste, compostable materials
4. EcoWaste (waste_type: 4) - Electronic waste, batteries, hazardous materials
Please respond with ONLY a JSON object in this exact format:
{
"waste_category": "category_name",
"waste_name": "specific_item_name",
"waste_type": number
}Method 1: Local Inference on the Raspberry Pi
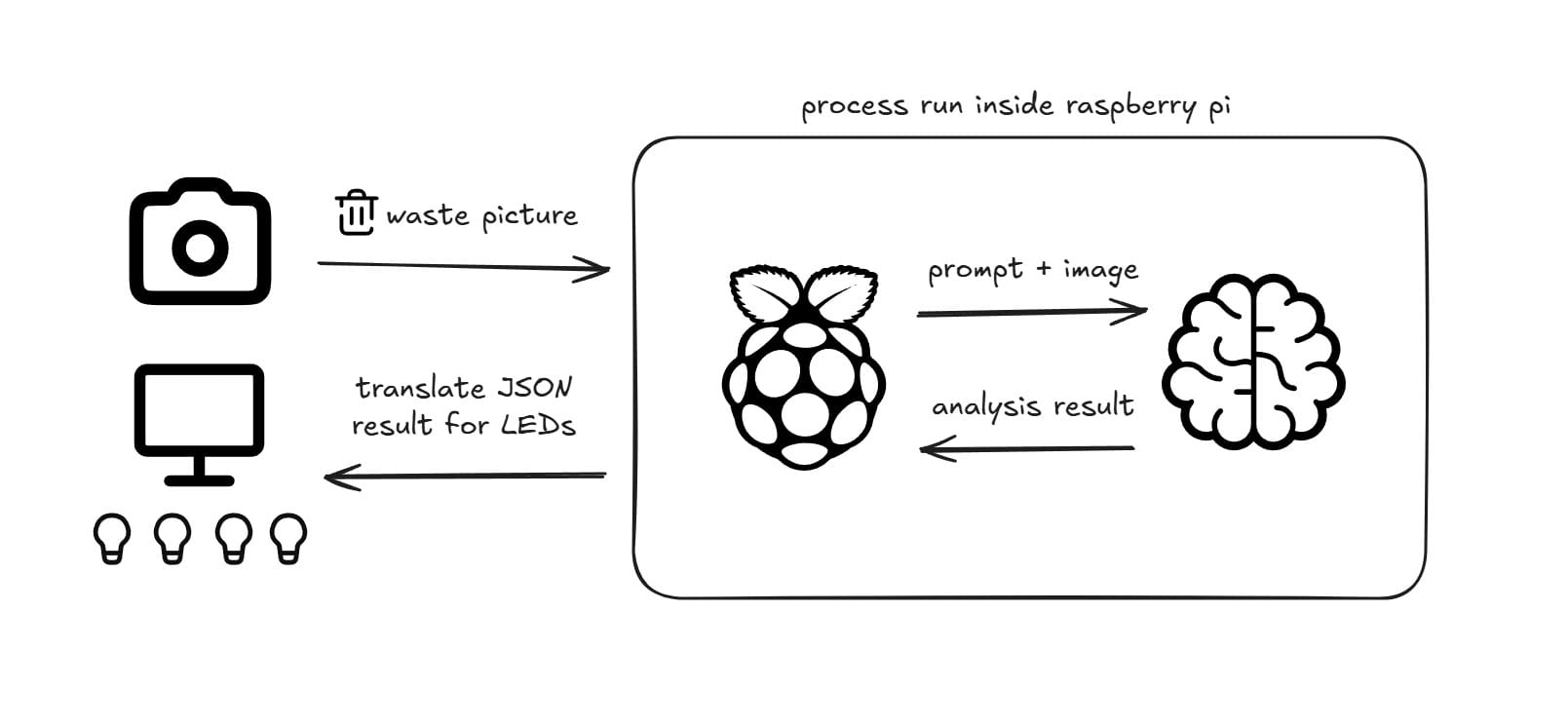
As with many tinkering projects, the quickest way to get an inference engine running is with tools like Ollama or LM Studio. They offer a fantastic, user-friendly experience. For this project, I chose Ollama because of its simplicity and excellent support for Linux, which is perfect for the Raspberry Pi.
The setup was straightforward:
- Install Ollama for Linux.
- Pull the moondream:1.8b model.
- Run our classification script.
Method 1 Result
I tested the setup by capturing an image of a banana. Here's a log of the process:
Camera feed started.
Capture button pressed on GPIO 26. Capturing image...
Image saved as image_1758513734.jpg
Camera feed stopped and resource closed.
Classifying image: image_1758513734.jpg
Sending request to http://localhost:11434/api/generate...
Classification result: organics - banana peel (Type: 3)
Total processing time: 61.81 seconds (1.03 minutes)
Activating Green LED for Organics.The result was impressive! The model correctly identified the item as "organics." However, I noticed that its ability to name the specific item ("banana peel") was inconsistent, likely due to variations in lighting and angle. But for our core task of categorization, it worked reliably. The main drawback was the processing time: just over a minute.
Is that fast enough? Or do we need more power? Yes, we need more power!
Method 2: Remote Inference on a Dedicated GPU
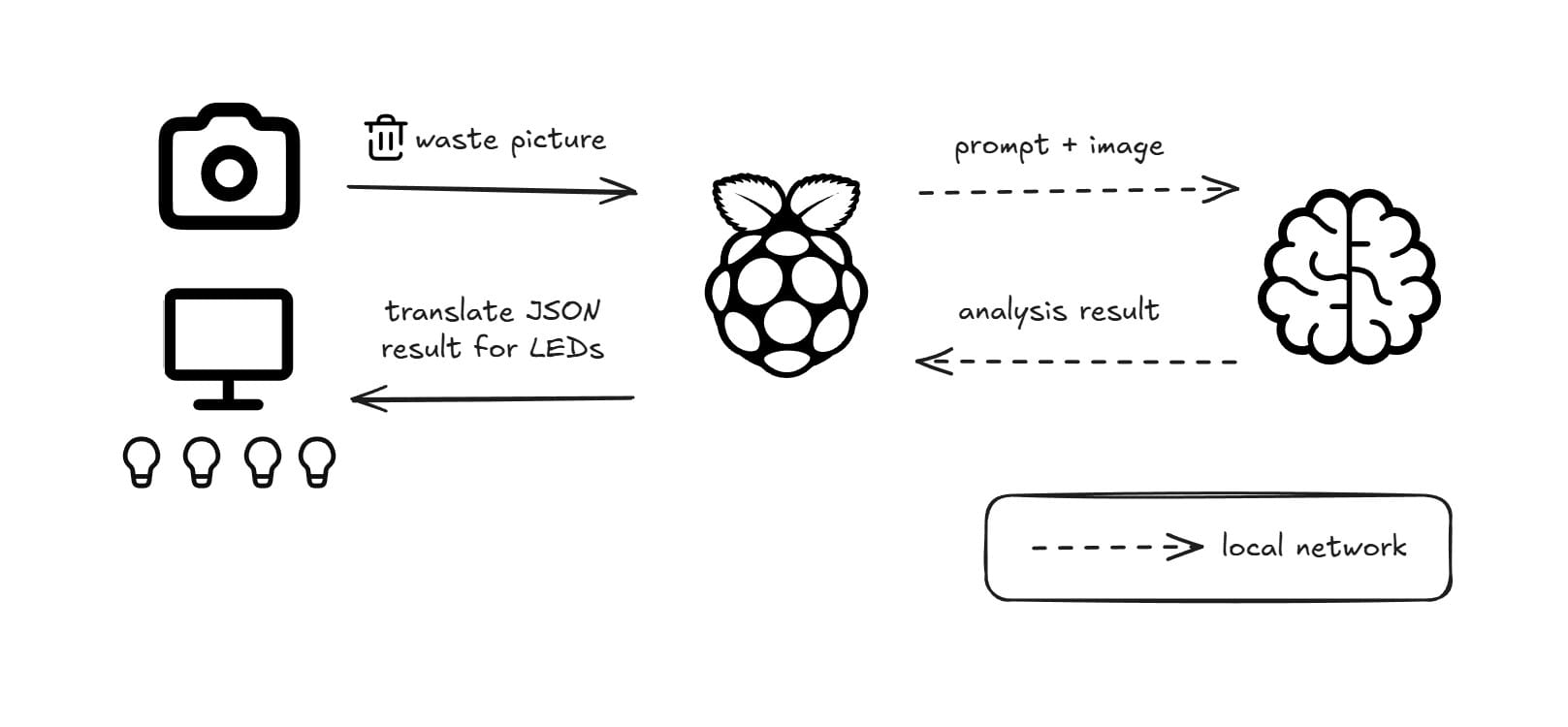
This method involved a simple change in the script: pointing the request URL to the IP address of my other PC. Of course, a few setup steps were required on the host machine:
- Download the desired vision model, in this case, qwen2.5vl:7b.
- Configure Ollama to accept requests from other computers on the network by setting the OLLAMA_HOST environment variable to 0.0.0.0.
- Restart the Ollama server for the changes to take effect.
Method 2 Result
Camera feed started.
Capture button pressed on GPIO 26. Capturing image...
Image saved as image_1758514515.jpg
Camera feed stopped and resource closed.
Classifying image: image_1758514515.jpg
Sending request to http://192.168.8.111:11434/api/generate...
Classification result: Organics - banana (Type: 3)
Total processing time: 1.06 seconds (0.02 minutes)
Activating Green LED for Organics.The difference was night and day. The processing time dropped from over a minute to just one second. This isn't a fair comparison, of course, my PC's RTX 5070 Ti is in a different league than the Raspberry Pi's onboard processing. While we hope to see this kind of speed on edge devices in the future, it's not yet possible with this generation of hardware (though an Nvidia Jetson Orin Nano might be an interesting future test!).
The Qwen-VL model also proved to be far more consistent, correctly identifying the object even in dim lighting or at odd angles, something Moondream struggled with. This is understandable, given the significant difference in model size (7 billion vs. ~2 billion parameters). Nonetheless, for a non-critical hobby project, the performance of the Moondream model on the Pi is more than sufficient.
Prototype Result
Key Takeaways from this Phase
This phase was more than just a technical exercise; it was a practical exploration of the trade-offs in modern AI development.
- Small Models Punch Above Their Weight: The emergence of capable, efficient models like Moondream is a game-changer for edge computing. This project proves you don't need a massive, power-hungry model for effective, real-world tasks. Local, on-device inference is more practical than ever.
- The "Right-Sizing" Principle is Crucial: This experiment highlights the classic engineering trade-off between performance, cost, and power. While the large model on a GPU was blazingly fast, the small model on the Pi was perfectly adequate. It’s a reminder to "right-size" your solution and ask if the extra speed is worth the added cost and complexity. For many applications, the answer is no.
- AI is More Accessible Than Ever: The combination of affordable hardware (Raspberry Pi), user-friendly inference engines (Ollama), and open-source models has dramatically lowered the barrier to entry. A project that would have required a specialized team just a few years ago can now be prototyped by a hobbyist over a weekend. If you have an old Pi gathering dust, now is the time to give it a new life!
- Multimodality is Ready for the Real World: This project takes a physical input (an image of trash) and uses a VLM to generate a structured, actionable output. It’s a tangible demonstration that multimodal AI is no longer just a research concept but a practical tool for solving everyday problems.
What's Next?
The complete script for this phase, which adds the VLM connection to our previous phase 1 code, is available on the GitHub repository here.
This is just Phase 2 of a multi-phase journey. Coming up:
- Phase 3: We'll explore either deploying to the cloud or implementing RAG (Retrieval-Augmented Generation) to improve classification accuracy with custom data.
- Phase 4: I'm tempted to build an agentic framework (perhaps with LangChain) and implement observability to monitor requests and results for future improvements.
This is part of an ongoing series documenting the development of an AI waste classification system. Follow along for updates on each phase of the journey!

