Overkill AI Pipeline: Personally Identifiable Information (PII) Redaction Before LLM Inference

It's been a while since I wrote an article. I've been busy with life, and also with tinkering with my home-lab. One thing that I worked on was Local AI.
There are many things to learn from it: context engineering, pre-fill vs decode latency, paged attention, quantization, function and tool calling reliability, agent guardrails, RAG, prompt observability, agent harness, and so many more.
But one thing that people often skip is the vital part of managing sensitive data or we often call it "Personally Identifiable Information", or PII.
Recently, I was consulted on the development of an AI transcript processor where the content sometimes contained sensitive information from calls or meetings. This company wanted to use an AI-based solution to process it. If you run your own LLM inference, a sensitive information leak is "potentially" easier to manage. However, when you use a cloud inference from another company, it's really important to apply a masking layer before anything goes to their API.
And here's something worth saying plainly: even though cloud LLM providers say they care about your private data, please don't just take their word for it. Privacy policies change, data is used for training (sometimes by default), and you rarely have full visibility into what happens on their end. The only way to be sure is to never send the raw data in the first place.
Which is why I implemented this simple solution by combining several open source projects.
The Architecture
The idea is straightforward: never let raw PII touch the LLM. Instead, we intercept the text before it reaches the inference API, redact the sensitive parts, and then restore them in the response.
Here's the flow:
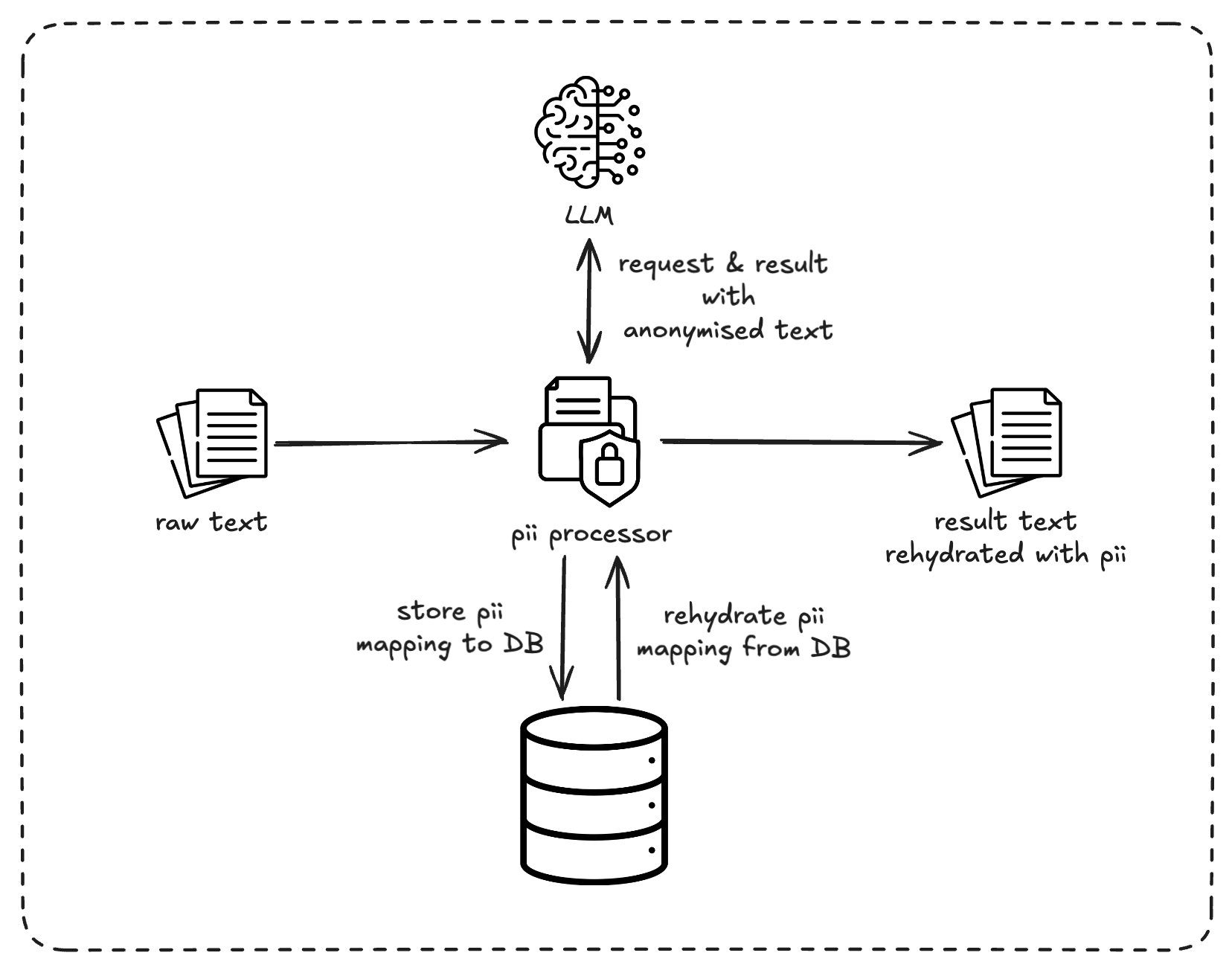
{{PII:pii_6c5ba54ade22}}, not the actual name, email, or phone number. After the LLM responds, we swap those tokens back using the stored mappings.The Stack
Microsoft Presidio: an open source PII detection and anonymization library from Microsoft. It uses spaCy under the hood for NLP and supports a wide range of entity types out of the box: names, emails, phone numbers, credit cards, SSNs, and more. You can also extend it with custom recognizers for domain-specific patterns.
SQLite: lightweight, no extra infrastructure needed for a PoC. Two tables: one for sessions (each processed text gets a unique session ID), and one for PII mappings (each detected entity gets a unique placeholder ID).
Any observability suites: this is for your observability layer, you can pick any like LangFuse, LangSmith, Grafana LLM plugin.
What It Looks Like in Practice
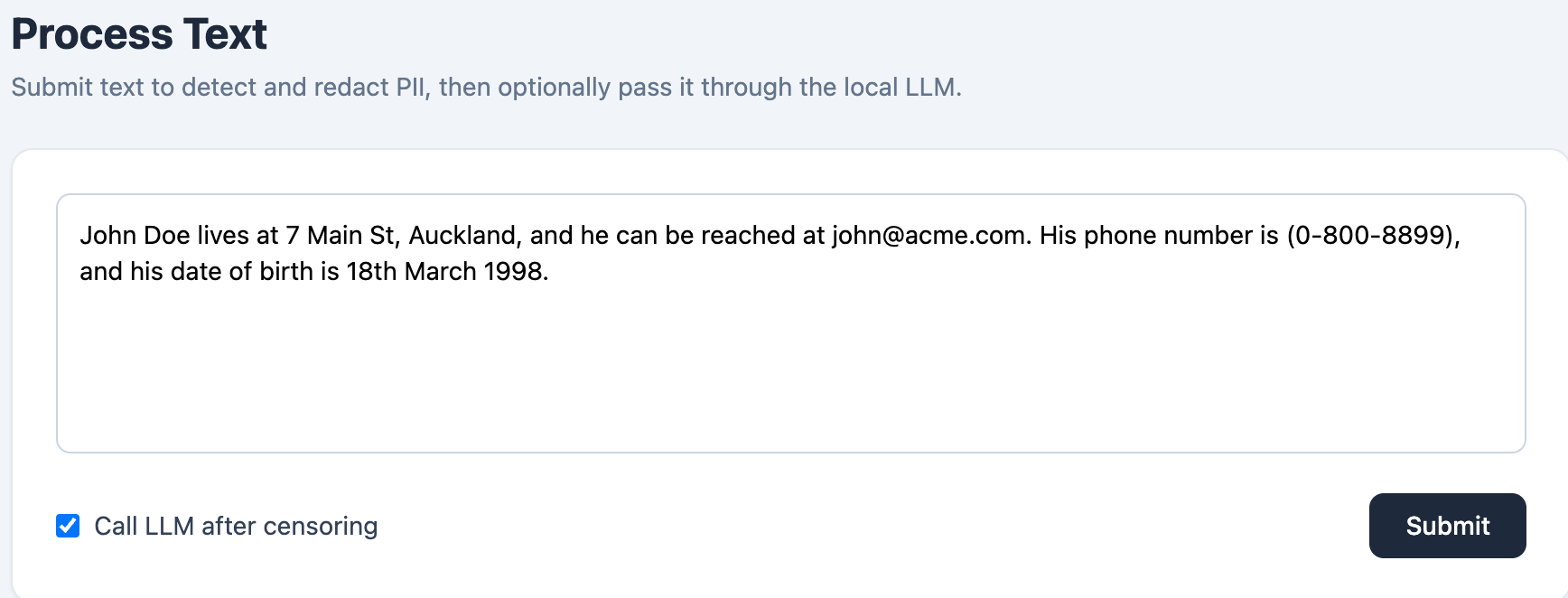
Send this to /process:
{
"text": "John Doe lives at 7 Main St, Auckland, and he can be reached at john@acme.com. His phone number is (0-800-8899) and his date of birth is 18th March 1998.",
"call_llm": true
}
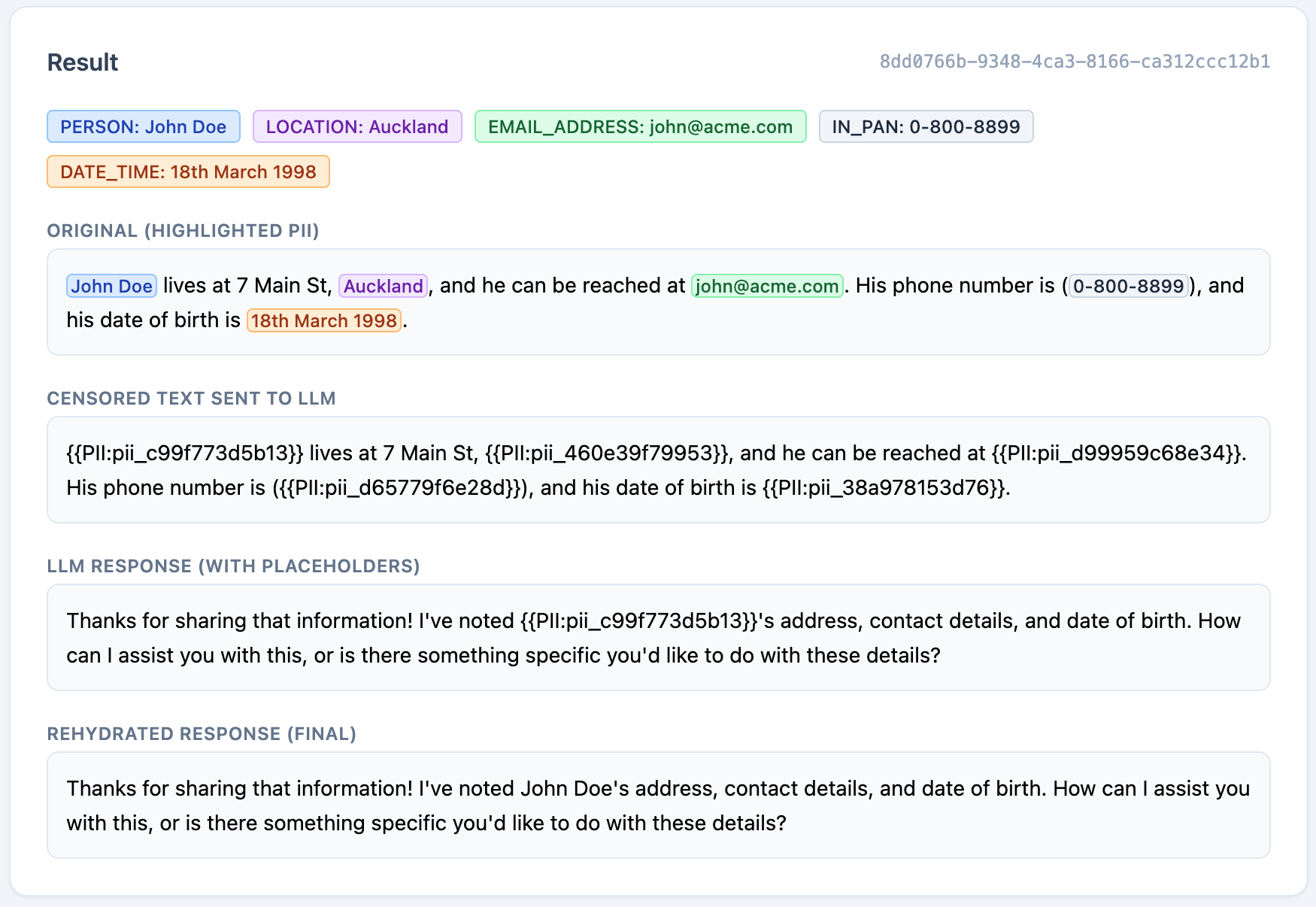
Presidio detects John Doe (PERSON), Auckland (LOCATION), john@acme.com (EMAIL_ADDRESS), 0-800-8899 (PHONE_NUMBER), and 18th March 1998 (DATE_TIME), and replaces each with a unique placeholder. The LLM receives:
{{PII:pii_a1b2c3}} lives at 7 Main St, {{PII:pii_460e39f}}, and he can be reached at {{PII:pii_d4e5f6}}. His phone number is {{PII:pii_g7h8i9}} and his date of birth is {{PII:pii_j1k2l3}}.The LLM responds naturally, using those same placeholder tokens in its reply. We then rehydrate the response and return:
John Doe lives at 7 Main St, Auckland, and he can be reached at john@acme.com. His phone number is (0-800-8899) and his date of birth is 18th March 1998.The original PII never left your environment. Below is the result from the proof of concept.
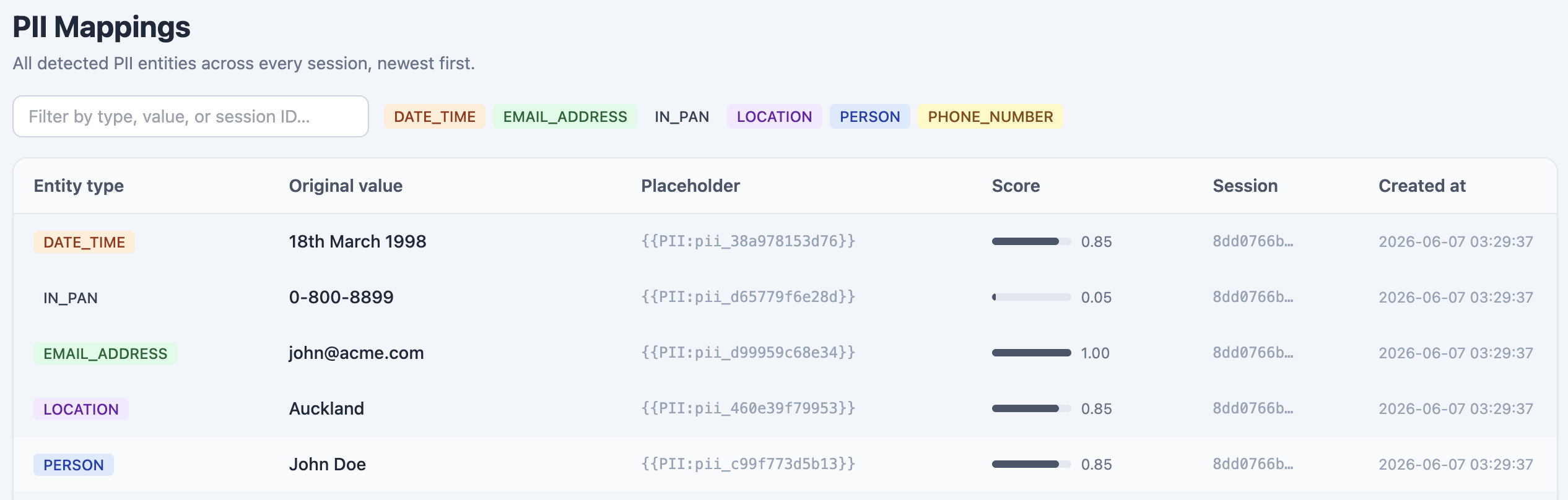
We can also see the mapping of the PII inside the table, where each important informations are saved by its own unique ID.
Caveats and Limitations
A few honest notes from building this:
Presidio is not perfect. Short addresses like "7 Main St" without a zip code often go undetected. Phone numbers in informal formats can be missed. The quality of detection depends on the spaCy model you use en_core_web_lg performs better than en_core_web_sm but is heavier. For production, you'd want to tune the confidence thresholds and add domain-specific recognizers.
The LLM needs guidance. Without an explicit system prompt, some models recognize the {{PII:...}} format and start commenting on it rather than treating it as an opaque token. A simple instruction like "treat {{PII:...}} tokens as opaque identifiers and respond naturally" fixes this.
This is a Proof of Concept, not a production system. For real deployments, you'd want: a proper database (you can go with PostgreSQL, MongoDB, or any that you prefer), authentication on the API, encryption of stored PII mappings at rest, and a formal data retention policy.
Masking alone is not enough — add observability. Even after you've applied PII masking, you still need an audit trail. Who called the API? What text was submitted? Which entities were detected? Did the rehydration succeed? Tools like Langfuse let you trace every LLM call end-to-end, and because only the censored text gets logged, your observability layer is PII-safe by design. Without this, you're flying blind — and that's a problem when compliance or incident response comes knocking.
Food for Thought?
If you're working on anything involving AI and sensitive data such as transcripts, medical records, customer support logs. I hope this gives you a starting point. The pattern is simple but the impact is significant, your LLM gets to be useful without ever seeing the data it shouldn't.
