Natural Language Processing in Map Client: A Proof of Concept

Overview & Goals
As Large Language Models (LLMs) are released almost monthly, many businesses are eager to integrate "AI" into their operations. While I believe that not all processes require AI implementation, and many current AI implementations are simply sophisticated, fancy automation, LLMs excel at natural language processing. With models becoming smaller and more efficient, we can now host them locally using numerous open-source options. This article explores my journey in staying current with AI developments and experimenting with practical applications.
In my field of work, the representation of geospatial data on maps is a crucial component of many applications. Observing how LLMs continue to improve while becoming more resource-efficient, I became curious about how AI could enhance map interactions. This led me to develop a proof of concept for natural language processing in map clients.
The Vision: Natural Language Map Interaction
Currently, map interactions rely primarily on traditional input methods: mouse clicks, hover events, drag operations, and touch gestures on mobile devices. But imagine typing commands like:
- "Can you show me features A for the New York area?"
- "Could you play the radar animation for Australia?"
- "Hide all traffic layers and zoom to downtown San Francisco"
The map would then automatically adjust the view, toggle layers, and execute your requests. Essentially, becoming your intelligent geospatial assistant.
Technical Foundation
LLMs cannot directly interact with client-side mapping libraries (MapLibre, OpenLayers, Leaflet, etc.). However, we can leverage structured output or controlled generation to make LLMs produce specific formats like JSON, XML, or YAML.
For example, we can prompt the model with something like this:
Return a user profile in the following JSON structure:
{
"user": {
"name": "string",
"age": number,
"skills": string[]
}
}With that in mind, let's go through what we need next.
Core Architecture Requirements
For our map NLP system, we need:
- Structured JSON Output Format:
{
"operation": "show|hide|play|stop|pan|zoom|unknown",
"layerId": "layer_identifier",
"boundingBox": [
"topLeftLatitude",
"topLeftLongitude",
"bottomRightLatitude",
"bottomRightLongitude"
]
}- API Infrastructure: A simple REST API that receives natural language prompts and forwards them to LLM inference services (cloud providers, local Ollama, Llama.cpp, or LM Studio)
- Client-side Integration: JavaScript handlers that parse the JSON structure and execute the corresponding map operations
Evolution Through Four Iterations
First Iteration: Prompt Engineering
The initial approach uses a single LLM call with a comprehensive context embedded in the prompt. This straightforward method requires manually curating all necessary information—available layers, supported operations, geographic boundaries, and business rules—directly into the prompt text. While simple to implement, this approach relies entirely on the model's ability to understand and correctly apply the provided context without external verification or dynamic updates. Some models with large parameters are quite good at interpreting user requests, while others aren't. So it's really important to pick the right model and compose the prompt carefully.
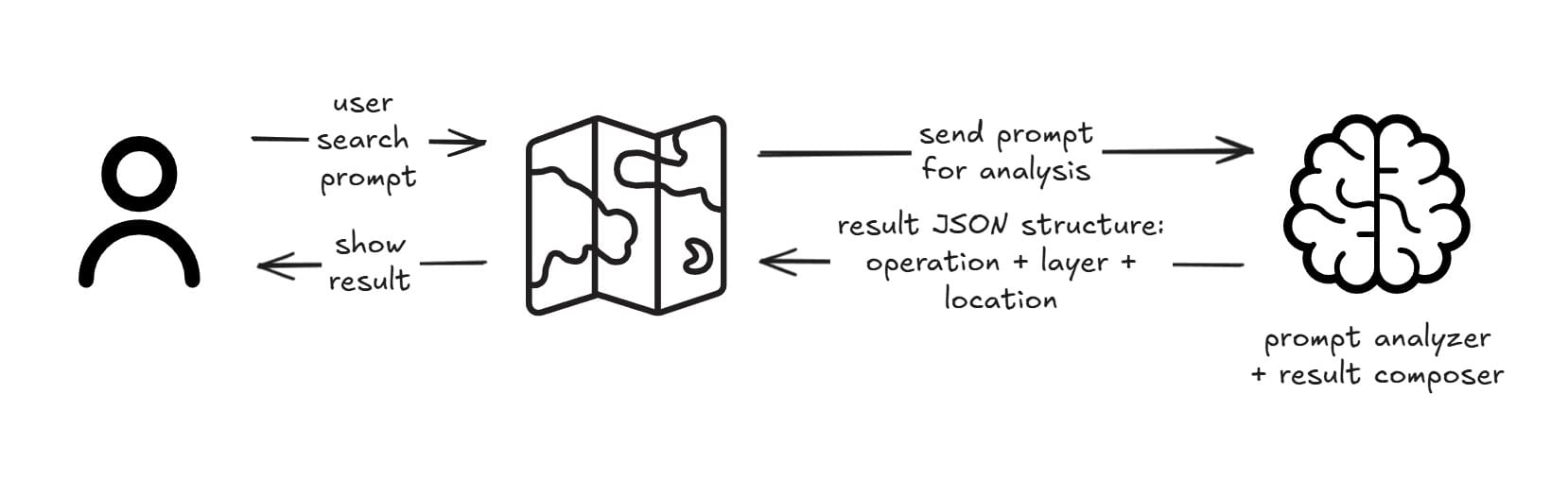
Implementation Requirements:
- Complete Operation Catalog: Document every supported operation with clear descriptions
- Layer Registry: Maintain an exhaustive list of available layer IDs with metadata
- Guardrails: Implement prompt injection protection and error handling
Example Prompt Structure:
You are a map assistant.
Available operations: show, hide, play, stop, zoom, pan.
Available layers: traffic_live, weather_radar, satellite_imagery, poi_restaurants.
Respond only with valid JSON. If uncertain, use "operation": "unknown".
User request: "Show me traffic in downtown Seattle"However, this iteration could have some limitations:
- Hallucination Risk: Models may invent non-existent layer IDs or operations
- Context Window Constraints: Large layer catalogs may exceed token limits
- Static Knowledge: Cannot access real-time layer availability or metadata
For this, we could implement something that is called Tool Calling.
Second Iteration: Tool-Enabled Architecture
This evolution introduces dynamic data retrieval through LLM tool calling capabilities. Instead of embedding all possible layer information and location data directly in the prompt, the model can now actively query external systems when needed. This approach transforms the static prompt-based system into a dynamic one that can access real-time layer availability, fetch current geographical data, and adapt to changing map configurations without hitting context window limits.
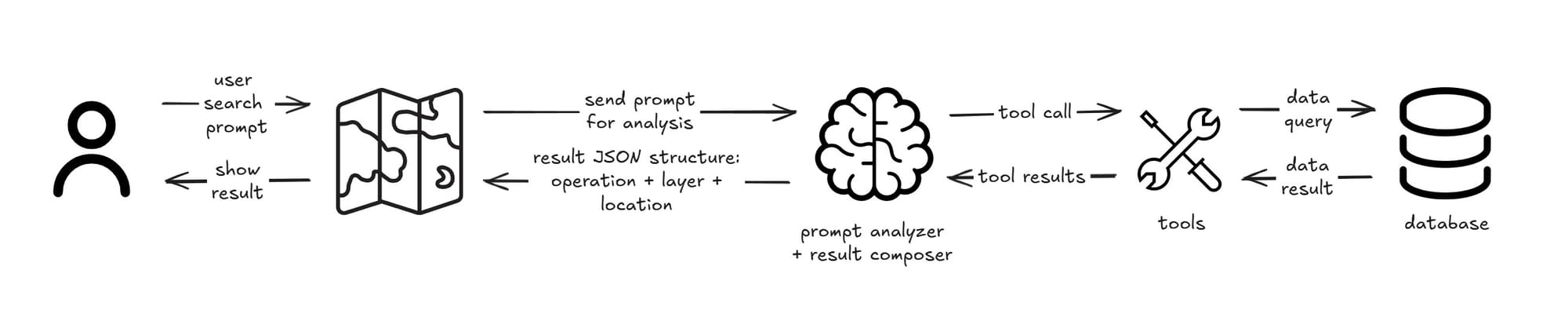
To achieve this, we will need adjustments in our implementation:
- We need to pick a model that can do tool calling (not all models support this). Make sure you do your research when picking up this model.
- To make our lives easier, let's pick one of the existing agentic frameworks, such as smolagents (lightweight, fast), LangChain (comprehensive ecosystem), LangGraph (state management), or Microsoft Agent Framework (enterprise-focused)
- Defining all of the tools that we need. For example: "Retrieve layer id" and also "Retrieve specific location".
Security Considerations:
AI systems require a meticulous security implementation checklist, as they introduce unique attack vectors beyond traditional web applications. Unlike conventional systems, AI-powered applications are vulnerable to prompt injection attacks, data poisoning, and model extraction attempts. Each component, from input validation to model inference, must be hardened against both traditional exploits and AI-specific threats. Some things we could do:
- Implement API authentication even for LLM-only access
- Rate limiting and input validation
- Audit logging for all tool calls
However, this iteration raised one or more challenges:
- Data Privacy: Commercial LLM providers may retain prompt data for training
- Latency: Multiple tool calls increase response time
- Cost: Higher token consumption and API calls
To improve and take on these challenges, we could implement what we call Multi Agents.
Third Iteration: Multi Agents
To address privacy concerns, we could implement a hybrid approach using multiple specialized agents. Multi-agent systems involve multiple AI agents working together, each specialized for specific tasks. Unlike single-agent approaches, this architecture allows different agents to handle different aspects of the problem. Some might excel at language understanding, others at data retrieval, and others at decision-making. In our context, this means we can distribute responsibilities: use commercial LLMs for general language processing while keeping sensitive data processing on self-hosted models.
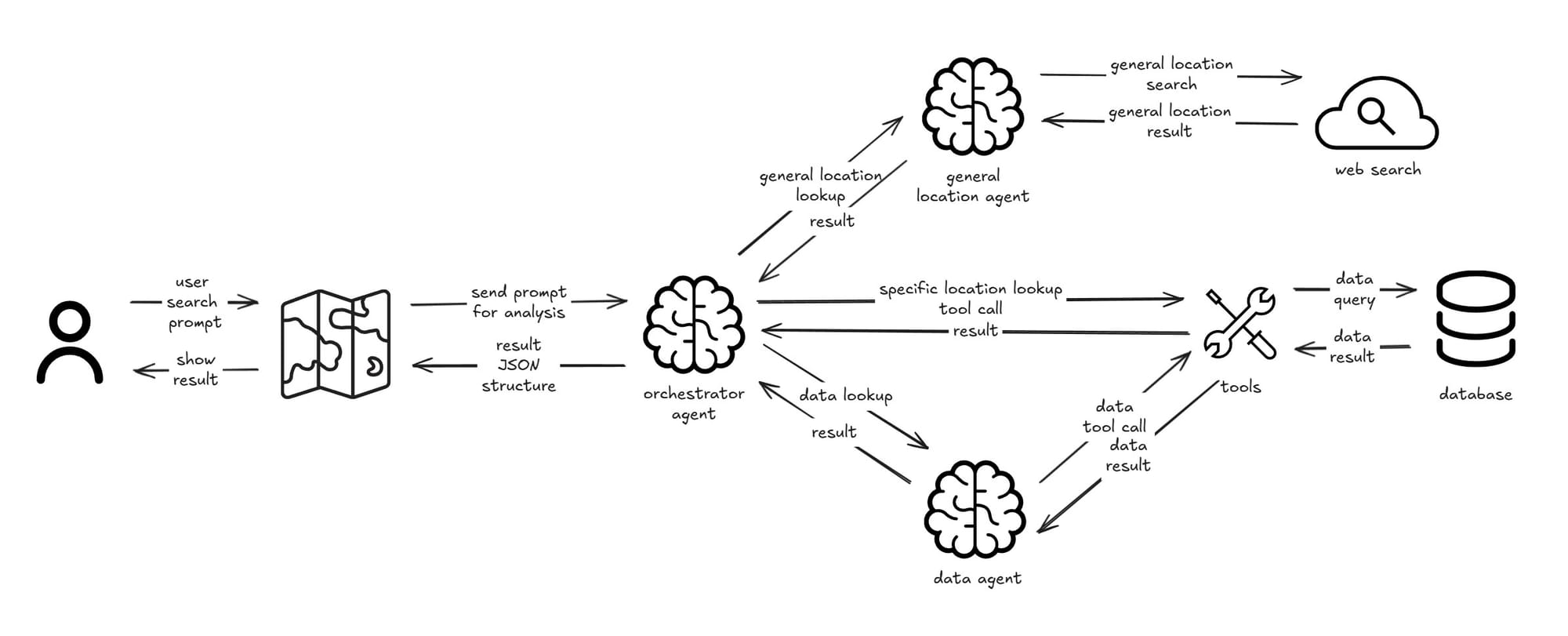
Agent Specialization:
- General Location Agent (Commercial LLM): Handles general geographic queries
- Data Agent (Self-hosted LLM): Manages sensitive internal data
- Orchestrator Agent (Self-hosted LLM): Analyze what location needs to be looked up, pass on a general location agent or tool call for company-related location, also combine context from other agents to be the final structured output for the map.
Benefits:
- Data Sovereignty: Sensitive data never leaves your infrastructure
- Flexibility: If needed, we can mix commercial and open-source models based on requirements
- Compliance: Easier to meet regulatory requirements
We could end this version, but surely we need to measure and observe all prompts to make sure we have all the metrics and traceability that we need for a successful AI solution.
Fourth Iteration: Observability
A production-ready system requires comprehensive monitoring and observability to ensure reliability, performance, and continuous improvement. Unlike traditional applications, AI-powered systems introduce unique challenges: model outputs can be unpredictable, token costs fluctuate with usage patterns, and multi-agent coordination adds complexity layers.
Observability becomes critical for understanding not just if the system works, but how well it understands user intent, why certain decisions were made, and where improvements can be implemented. This iteration focuses on building visibility into every aspect of the AI pipeline—from user prompts to final map actions.
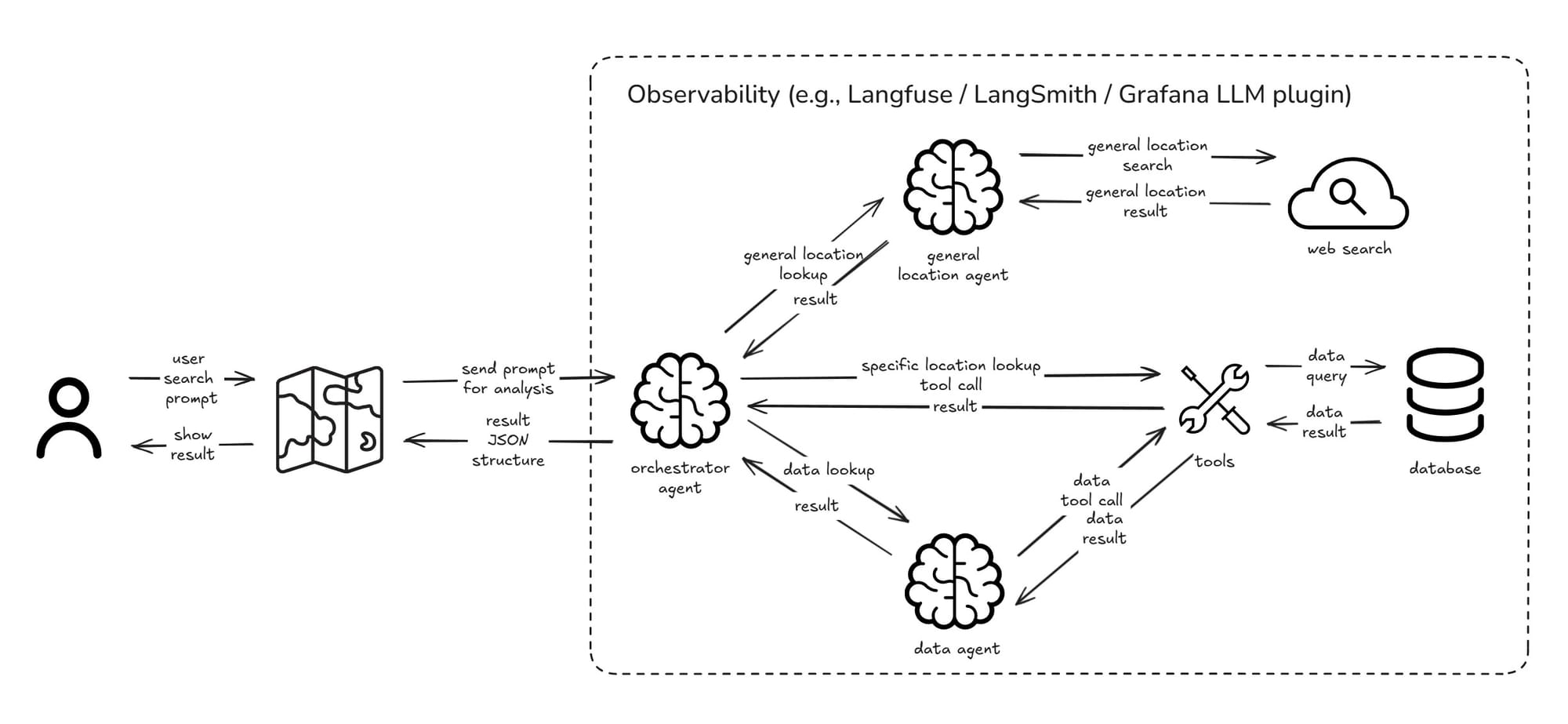
Key Metrics to Track:
Some notable metrics usually done to track an AI solution, below are some of those divided by their categories:
- Performance Metrics focus on system efficiency: monitoring response times (95th percentile latency), tracking token usage per request to control costs, measuring coordination overhead between multiple agents, and analyzing cache effectiveness to optimize repeated queries.
- Quality Metrics ensure accuracy and user satisfaction: measuring how well the system understands user intent, validating that generated JSON outputs are properly formatted, collecting user feedback scores, and categorizing different types of errors to identify improvement areas.
- Business Metrics demonstrate value and adoption: tracking feature usage rates to understand user engagement, analyzing query complexity trends to guide system improvements, measuring user retention specifically for NLP features, and calculating cost-per-interaction to ensure economic viability.
Quick Proof of Concept Demo
I've recorded an early version of this proof of concept that shows how the LLMs could interact with the MapLibre mapping framework.
Proof of concept in action
What's Next for Future Improvements?
This proof of concept only scratches the surface of what potential that we could implement for interaction with geographical data inside a mapping solution. More improvements could be done in the future, such as:
- Multimodal Integration: Combine natural language with gesture recognition, or maybe combine it with a speech-to-text model so the user could just "speak" to our map solution.
- Contextual Awareness: Learn from user behavior and preferences. As we don't know what our clients will do with this feature, whether they'll use it, what type of prompts they frequently use, and many other things to look for.
- Real-time Collaboration: Multiple users issuing commands simultaneously, because every application needs frequent assessment of further scaling requirements.
- Advanced Analytics: Predictive queries based on temporal patterns could improve our implementations, maybe by changing our prompting techniques or adding more specialized agents.
Conclusion
Natural language processing in map clients represents a significant evolution in geospatial user interfaces. Through iterative development—from simple prompt engineering to sophisticated multi-agent architectures with comprehensive observability—we can create systems that are both powerful, trustworthy, and hopefully frequently used.
The key to success lies in balancing innovation with practical considerations: data privacy, system reliability, user experience, and cost-effectiveness. As LLM technology continues advancing, the possibilities for intelligent map interactions will only expand.